Welcome To My Blog
Everything WordPress, and More
My personal space for me to geek out on web technologies and keep myself sharp by writing about topics related to business, WordPress, and The Web.

What is a WordPress Care Plan?
Explore what a WordPress care plan covers, including security, updates, optimization, and support. Learn how to choose the right plan for your website.

How to Choose a WordPress Hosting Provider
Understand the key factors to consider when selecting a WordPress hosting provider, from performance and security to support and scalability.

Transparent, Flexible Pricing at WildPress
WildPress' flexible billing options - fair and transparent rates for your web projects.

A Short Guide to WordPress Video Hosting
Should you self-host or use a video hosting platform like Vimeo or YouTube? Let's dive in!

Why choose Hugo?
Why choose Hugo for your next website build? Lightning-fast load times, top-notch security, straightforward content updates, consistent site design, and limitless hosting options.
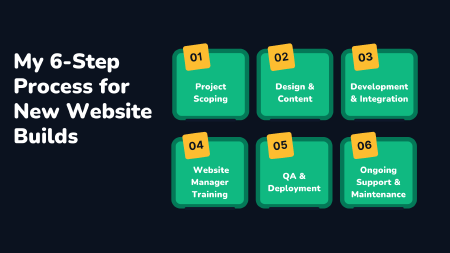
My 6-Step Process for new Website Builds
Custom website builds often take 30-80 hours of solid development time. It's important to have battle-tested processes in place to manage large projects.
